


De-normalization, Data Consistency, and Events
On sharing data throughout big monolith app


De-normalization
In many cases, we would need to save de-normalized data in a database -SQL or NoSQL- to facilitate certain queries. Nevertheless, to keep the de-normalized data consistent we need to update them whenever the original data change.
For our case, let's say that module A has some values that modules B and C depend on, meaning that module A has some values that modules B and C need constantly.
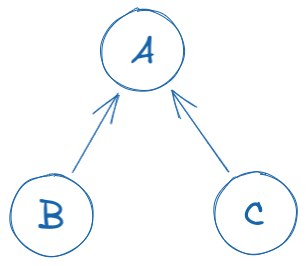
Accordingly we de-normalize the needed values in modules B and C. Now module A has some changes and we need to reflect those changes to modules B and C. How do we do that?
Data Consistency
The Traditional Way
The first thing that would come to our mind when we face this problem is to update modules B and C through module A whenever a change happens in module A.
So, in an LMS (learning management system), if we de-normalize the school's name (module A) into the courses model (module B) and classes model (module C). We design the service that is responsible for changing the school name such that it updates the related courses and classes as well. And if we decide to de-normalize some school value into semesters as well (some other module D), we would need to update the semesters too in the schools' update service.
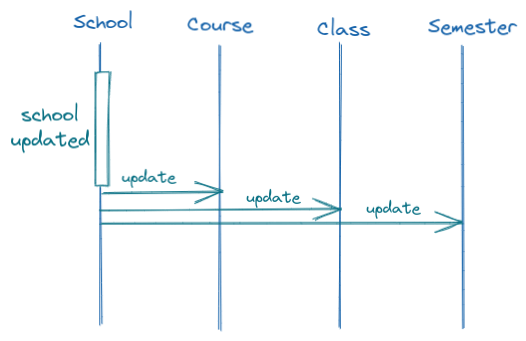
This is very straightforward and gets the job done. But soon we see the problems when we spread the de-normalization across the system.
On one hand, we couple the schools module, which is a high-level module, with the low-level courses and classes modules, and this is a violation of the dependency inversion principle.
On the other hand, there is always the problem of documenting the de-normalized fields. They are often documented or marked as de-normalized in the dependent module and not in the dependency. This makes sense, as I would want to know which fields represent the relations and which fields are just de-normalized. But when we need to design the update service for the dependency module, we would need to check the documentation (if any) of every module in the system to make sure that we updated everything and nothing is left behind.
Another problem that this solution introduces, is that when we need to introduce a new de-normalization for a field that is being updated by some other service, we would need to update that service to include the new module as well. So to de-normalize values from module A to module D as well, we would need to update the services of module A. This is a strong violation of the Open-Closed principle.
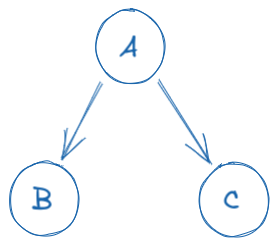
And yet another problem is that we introduce circular dependency between the modules, as now module A depends on modules B and C (to update them) in addition to their initial dependency on A from the beginning, which is not a disaster on its own, but it's an obvious architectural smell.
Using Events
Inspired by the async communication methods between microservices, and by the Saga pattern. I would propose keeping consistency between modules in the same application (whether it is a microservice or a monolith app) using events and a simple -internal- event bus.
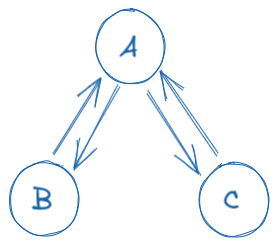
For the example we saw earlier, where module A is a dependency for modules B and C: We just need to use a simple event bus and emit an event from module A whenever there is an update. Modules B and C would then subscribe to the event bus for events from module A (and any of their dependencies) and update their information according to the updates in module A.
This will make all of (A, B, and C) depend on the event bus instead of having a circular dependency like earlier, now the dependency graph would look something like the following...
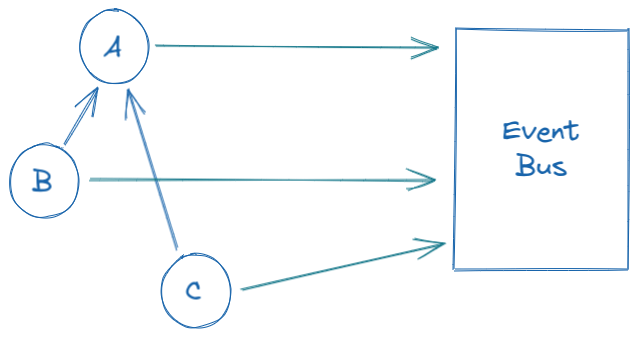
Although this may seem too much of an overhead, or even may seem like a trivial change in the architecture. It has a lot of benefits...
First, there is no more coupling between module A and its dependents B and C. When a module needs to include some de-normalized data from another module, it's the responsibility of the dependent module to keep its data consistent, and not the responsibility of the dependency. So no more violation of Dependency Inversion principle.
Second, when we design a service to do some updates on module A we are not concerned about other modules that depend on it. We just emit the right events and other modules update themselves through their event listeners, this enhances the developer experience with the code base and solves the problem of The circular dependency.
Third, whenever we need to de-normalize the fields of module A into another module D, we do not make any updates in module A, we only add a new listener to the event bus for module D. So module A is now open for extension and closed for updates. So we satisfy the Open-Closed principle.
Handling the updates with events comes with costs, as we would need to use an event bus to communicate between the different modules, and we would also need to maintain and document the events, and keep their structure updated throughout the various migrations that would happen to the dependency modules (such as when module A gets a schema migration), but it offers a lot of flexibility and decoupling of modules that are not supposed to be coupled.
Using events also solves the problem when there is more than one level of dependency, like when module C depends on module B and module B depends on module A. And an update happened at module A that would require updates in both modules B and C. We can simply emit an event from module A to be read from module B, and when B is updated it would emit an event that would be read from module C. And this greatly simplifies the architecture of the project and responsibilities of each module.
It also solves the problem of locating services and passing them throughout the code for big and complex projects. And it enforces the separation of concerns principle as each module would address its own concern and not the whole system's.
Keep in mind that there would be other problems that would need to be solved, like handling concurrent updates on the same resource, or updating a large set of data due to an update in a module that has a lot of dependencies. These are some problems that would need to be addressed separately.
Lastly, using events is not a silver bullet that would solve all data consistency problems. But it can help along the way. Also, it can be an overkill for some simple cases where we are sure that there will ever be limited dependents.